Concept
I knew right away that I wanted to do a data visualization for my ICM final, mostly as a technical challenge, but I had a hard time coming up with a topic that was meaningful to me. Dano suggested that I spend some time thinking about a question that I wanted to ask, and use that as a way to frame the project. I sat with that for a while and found myself thinking about why I liked data visualization at all. I realized that I’m curious about how good visualizations can reveal not just what we know, but how we know.
In the US right now Wikipedia is treated like the repository of human knowledge, when in reality it’s far from it. When we check Wikipedia what we see is just a momentary record of the activity of adding, editing, and deleting information by contributors. It’s more of a reflection of things a certain group of people are interested in, rather than a record of everything that exists. (But maybe that’s what knowledge is anyway, we can only really learn about and experience a very limited slice of the world.)
I realized that I wanted to see if I could find ways that our understanding of the world was limited, to find the edges of our knowing and understanding. To that end, I decided to explore the possibility of unseen imbalances and limitations on Wikipedia. My original proposal was to create a mapping of all the event articles that could be scrubbed through by year. I was hoping to uncover under-documented regions and time periods, but I didn’t really know what I was going to find. I was asking a question, rather than making something that I had tightly planned out.
The technical end of this project was an interesting challenge. I had to know know what kind of data was available and how it was organized to create the visualization, but I had to know what kind of data scheme was best for the visualization in order to process the data. The result was that I had to work both ends of the project at once, without having a completely clear idea of how they would join together. It was kind of like digging a tunnel from both ends and having faith that they would meet in the middle. My process ended up being watching d3.js tutorials, working through example exercises, and researching the Wikipedia API without having a strict final project design in mind. I trusted that the correct visualization would become clear as I worked through the technology.
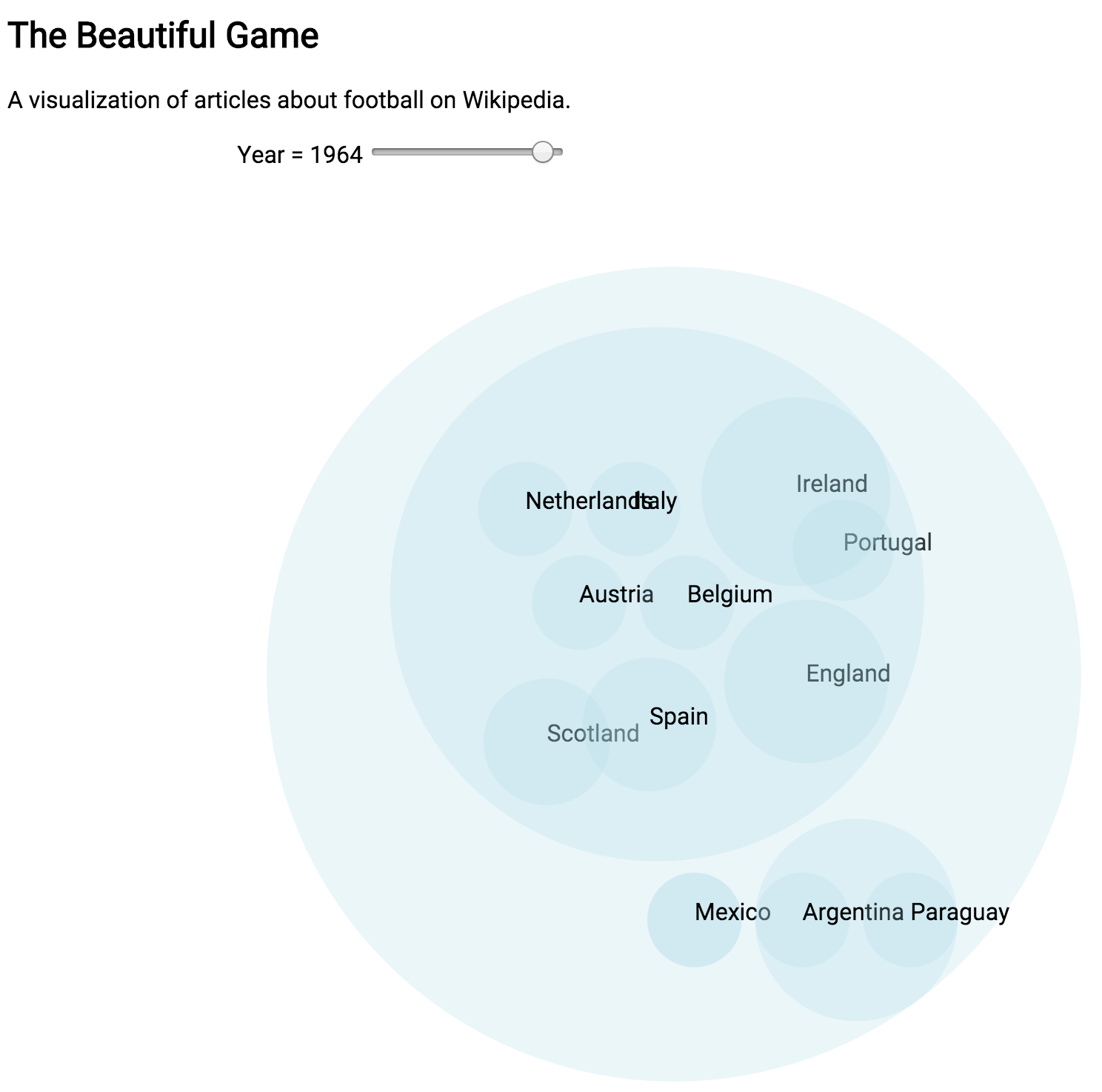
At a certain point I realized that I was going to have to scale back the dataset I was using for this project. Using all the history articles on Wikipedia is simply beyond the scope of my skills right now. I had to pick a slice of the data to use instead. There were a lot of options but I ended up going with soccer. I really liked this dataset because it was a manageable size, but also because I feel like it still encapsulates most of the original idea. Soccer a truly global sport with a long history. There’s also the sense that international rivalries that would have previously found an outlet in marital conflict can be settled on the soccer pitch.
Data
Wikipedia – My original desire was to create a visualization with live data using the Wikipedia API. It turns out that the wikipedia API is actually just the MediaWiki API, the wiki platform that Wikipedia uses, and is much better suited for gathering data about and manipulating the structure of Wikipedia, rather than reading its contents. (This awesome project for example).
Another option for getting the data straight from Wikipedia would be to scrape the site itself and create a custom dataset for the visualization. Many historical events have these great information boxes that summarize the event. Scraping the data out would get you everything you need to make a visualization. This approach is nice in that it would allow for complete customizability, but is bad in that it is extremely annoying. Scraping the data would not be that hard, the difficult part is that there is no information standardization on Wikipedia. Not all historical events have information boxes and there is a great deal of variation when they do exist. Scraping the data and putting it into a manageable form is really the kind of thing that you’d rather have someone else do for you. The good news is, someone already has
DBpedia & Wikidata.org – DBpedia and Wikidata.org are both projects that seek to take wikipedia contents and put it into a more searchable form. If you are looking for content from wikipedia for your application, using one of these is probably the way to go.
The problem that I ran into was that I had no idea how to query the data. Both projects use the SPARQL query language and store the data as RDF. Even after researching both SPARQL and RDF, I basically had no idea how to use either. Learning more about different query types seems like a great project for the future.
Static Data Sets – The easiest thing for me ended up being a static dataset released by DBpedia. The problem here was that the dataset was still absolutely huge; there were several I couldn’t even open. Also, after looking at them it became clear that the data would need a lot of cleanup. The location data was not all in the same format and would need to be normalized. I ended up doing a lot of this work manually in a spreadsheet and then using a pivot table to sort the data into a more useful form. Then I turned that information into json for the visualization.
Visualization
d3.js – I really wanted to learn d3.js. In many ways this project was created as an exercise to learn the technology. I did this mostly through the examples, documentation, and youtube tutorials. The technology is pretty straightforward, as long as you want to make something that they’ve already built. Deviating from what they’ve designed causes issues.
One difficulty I ran into with d3.js is that method chaining makes it difficult to debug. it’s hard to print something to the console to see if your data is being loaded correctly. Though, it seems like this is really something that will get better with more practice.
What’s Next
Learning how to read and update text & Getting better at manipulating datasets – This project really ended up being a data project rather than a visualization and it would have gone a lot faster if I could have done more of the data manipulation programmatically.
Think more about design – This project didn’t leave a lot of time for the design and layout considerations, which is honestly what I was really interested in. Going back and polishing this up later is going to be a good exercise.
Learn more d3.js – There is a lot of easy functionality here, making more charts,graphs and learning about transitions and animations seems like it will be a good skill for making complex interactive visualizations.
Leave d3.js behind – Truthfully, d3.js is a little boring. There’s a ton you can do with it, but there’s so much more that’s out there. I’d really like to be able to make whatever I imagine and that requires more than one javascript library.
Go further with Wikipedia data – Wikipedia is really interesting and really comes back to the core of what interests me in general. There was an example on Wikidata.org on how to list French people who have entries on english Wikipeida, but not on frech Wikipedia. That seems really interesting and I want to find out what kind of stuff is out there. Using Wikipedia as a framework for examining what we know and how we know seems very fruitful.